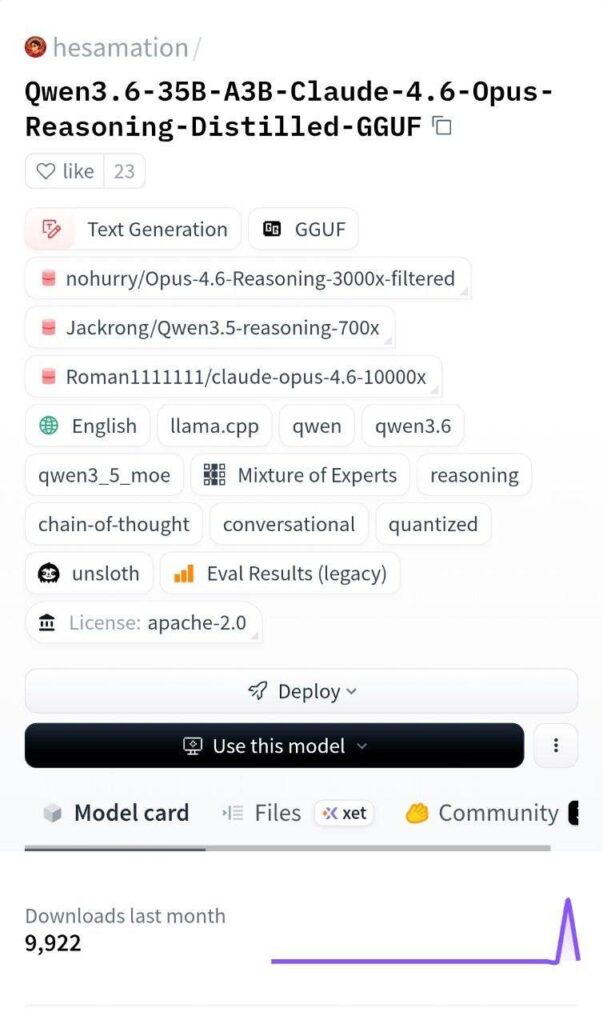
В сообществе активно распространяется ссылка на модель с названием Qwen3.6-35B-A3B-Claude-4.6-Opus-Reasoning-Distilled. Заявлено: бесплатная локальная модель, которая объединяет архитектуру Qwen с «знаниями» Claude Opus и превосходит закрытые аналоги.
Давайте разберёмся, что это на самом деле и стоит ли тратить время на тесты.
📋 Что заявлено в описании репозитория:
| Параметр | Заявленное значение |
|---|---|
| База | Qwen 3.6 (36B параметров) |
| Дообучение | Дистилляция с «Opus 4.6» (Claude) |
| Контекст/стабильность | До 12 часов непрерывной работы, эффективный расход токенов |
| Запуск | Локальный, через GGUF, развёртывание за ~5 минут |
| Доступ | Бесплатно на Hugging Face |
🔍 Фактчекинг: что здесь не так?
📌 Важно: на момент публикации ни Alibaba (создатели Qwen), ни Anthropic (создатели Claude) не анонсировали версии «Qwen 3.6» или «Opus 4.6».
| Утверждение | Реальный статус |
|---|---|
| «Qwen 3.6» | Официально последней стабильной версией является Qwen 2.5 / Qwen 3 (в зависимости от даты). Версия 3.6 не анонсировалась. |
| «Opus 4.6» | У Anthropic нет публичной модели с таким индексом. Веса Claude Opus закрыты и не доступны для легальной дистилляции. |
| «Уровень GPT‑5.4» | GPT-5.x не существует в публичном доступе. Сравнение некорректно. |
| «Дистилляция с Opus» | Технически возможно имитировать стиль через fine-tune на синтетических данных, но прямое копирование весов закрытой модели невозможно без доступа к ним. |
🤖 Что это может быть на самом деле?
Скорее всего, речь об одном из следующих сценариев:
- Неофициальный файн-тюн — энтузиаст дообучил открытую модель Qwen на синтетических данных, сгенерированных через API Claude, чтобы приблизить стиль ответов к «опусовскому».
- Маркетинговое название — длинное имя модели создано для привлечения внимания в поиске Hugging Face, но не отражает реальную архитектуру.
- Экспериментальная дистилляция — попытка передать «рассуждательные» способности через цепочки рассуждений (CoT) в обучающих данных, а не через прямое копирование весов.
🛠 Технические нюансы локального запуска:
✅ Формат GGUF — оптимизирован для запуска через llama.cpp, поддерживает квантование (снижение точности весов для экономии VRAM).
✅ 36B параметров — для запуска в 4-битном квантовании потребуется ~24-32 ГБ VRAM (или комбинация GPU+CPU). На обычном ноутбуке будет работать медленно.
✅ «12 часов работы» — скорее всего, имеется в виду стабильность инференса при длинных сессиях, но это зависит от реализации, а не от самой модели.
⚠️ Риски использования неофициальных сборок:
- ❌ Безопасность: пользовательские репозитории могут содержать модифицированный код. Всегда проверяйте хеши и отзывы сообщества.
- ❌ Качество: «дообучение на опусе» не гарантирует сохранения логики оригинала — возможны галлюцинации и деградация ответов.
- ❌ Лицензия: убедитесь, что файн-тюн соблюдает лицензии базовой модели (Qwen) и условия использования данных.
- ❌ Поддержка: неофициальные модели могут исчезнуть из доступа или перестать обновляться в любой момент.
🎯 Для кого это может быть полезно:
✅ Исследователи — эксперименты с архитектурными гипотезами и методами дистилляции
✅ Энтузиасты локального ИИ — тестирование пределов производительности на своём железе
✅ Разработчики прототипов — быстрая проверка идей без затрат на API-лимиты
❌ Продакшен-проекты — для коммерческого использования выбирайте официальные, документированные модели с поддержкой
🛠 Как протестировать безопасно:
- Проверьте репутацию автора репозитория на Hugging Face (история загрузок, отзывы)
- Скачайте только файлы модели (
.gguf), избегайте исполняемых скриптов - Запустите в изолированной среде (Docker, VM) для первичного тестирования
- Сравните качество ответов с официальной версией Qwen на вашем датасете
- Не используйте для обработки конфиденциальных данных до проверки безопасности
🔗 Репозиторий (на ваш страх и риск): Hugging Face: hesamation/Qwen3.6…
🔗 Официальные модели для сравнения: